Wavestone : l’IA en production
mardi 20 avril 2021
Wavestone est un cabinet de conseil français spécialiste de la transformation des entreprises et des organisations créé en 1990. Il est coté à la bourse de Paris. Il compte aujourd’hui 3 500 collaborateurs. Les deux intervenants, Cédric Goubard et Amine Charifi font partie de l’équipe Machine Learning & Datalab de Wavestone, créée il y a 5 ans, aujourd’hui composée de 45 data scientists.
Wavestone accompagne ses clients en combinant ses connaissances et ses expertises :
- Fonctionnelles : connaissance des métiers de l’entreprise (marketing, RH, ventes, stratégies, etc.)
- Sectorielles : connaissance des secteurs d’activité (banque & assurance, télécom, transports, énergie, etc.)
- Technologiques : connaissance et maitrise des technologies (architecture data, cloud, intelligence artificielle, cybersécurité, IoT, etc.)
Plus spécifiquement, le Machine Learning & Data Lab se spécialise dans l’accompagnement des différentes étapes d’un projet Data, de la définition de stratégie Data/IA jusqu’au déploiement à large échelle de cas d’usage Data/IA.
Qu’évoque pour vous la mise en production d’une IA ?
A été la question posée d’emblée aux étudiants en préambule de la conférence.

L’intervention s’est ensuite centrée autour de la présentation de trois cas d’usage réels :
- L’IA au service d’un métier – IA pour les Ressources humaines au sein d’un ministère
- Du notebook à la production – Traitement de tickets à la DSI de Wavestone
- Industrialisation avancée – MLOps chez un acteur de l’énergie
L’intelligence artificielle au service d’un métier
Le client de Wavestone était le service RH d’un ministère. Après une phase indispensable de cadrage avec le client pour comprendre le métier et la donnée disponible, quatre cas d’usage en sont ressorti :
- Profilage des postes : analyse de texte
- Qualification des appétences : détection d’arguments par le bais de tags
- Détection des postes désirés : identifier les postes et les relier à des postes à pourvoir
- Détection de groupes de candidats potentiels : constitution de viviers
Wavestone s’est focalisé sur les deux derniers cas d’usage via l’analyse NLP (Natural Language Processing) et la création d’un moteur de recherche pour détecter les appétences pour les mutations RH. Les données traitées par les algorithmes sont les fiches de mutation remplies par les administrés, et le but était de pouvoir extraire des « tags » et des analyses de sentiments. A noter que le moteur de recherche était basé sur l’outil Elastic Search. Il faut souligner qu’une partie importante du livrable dépasse le cadre du simple modèle de data science : explication des limites du modèle et recommandation d’architecture.
Projet ARTISTIC : ARTificial Intelligence System for TIcket Classification
« Du notebook à la production » : le client était cette fois la DSI de Wavestone, et l’enjeu était la classification initiale des tickets d’intervention IT créés lors de la survenue d’un incident. A l’époque des traitements manuels, cette classification était coûteuse, source d’erreurs et de délais. L’objectif était classique, celui d’une classification supervisée. La solution retenue est finalement basée sur une régression logistique, choisie car plus simple que les autres algorithmes testés et de performance comparable.
Industrialisation avancée (secteur de l’Énergie) : « ML Ops »
Il s’agissait ici de mettre en place une plateforme complète de data science capable de gérer tout le cycle de vie d’un projet depuis le POC (Proof of Concept) jusqu’à l’industrialisation. Ce genre d’outil mélange des étapes classiques de d’ingénierie logicielle et des étapes plus spécifiques de data science. Il se doit d’intégrer les concepts les plus récents de « Devops » et d’intégration continue venus du génie logiciel. Le but est d’aider le processus pour éviter l’écueil de « l’usine à POC » où tous les projets data science restent à l’état de prototypes sans aucune valeur ajoutée au final en production. En particulier, l’importance d’outils collaboratifs et de versioning (Git), de test (Pytest), de build, packaging, déploiement automatisés (Jenkins, Ansible, Docker) et d’orchestration/scheduling a été soulignée. Un soin tout particulier doit être apporté au monitoring du modèle après son déploiement en production, afin de détecter les dérives éventuelles, pour programmer des réentraînements automatiques par exemple.
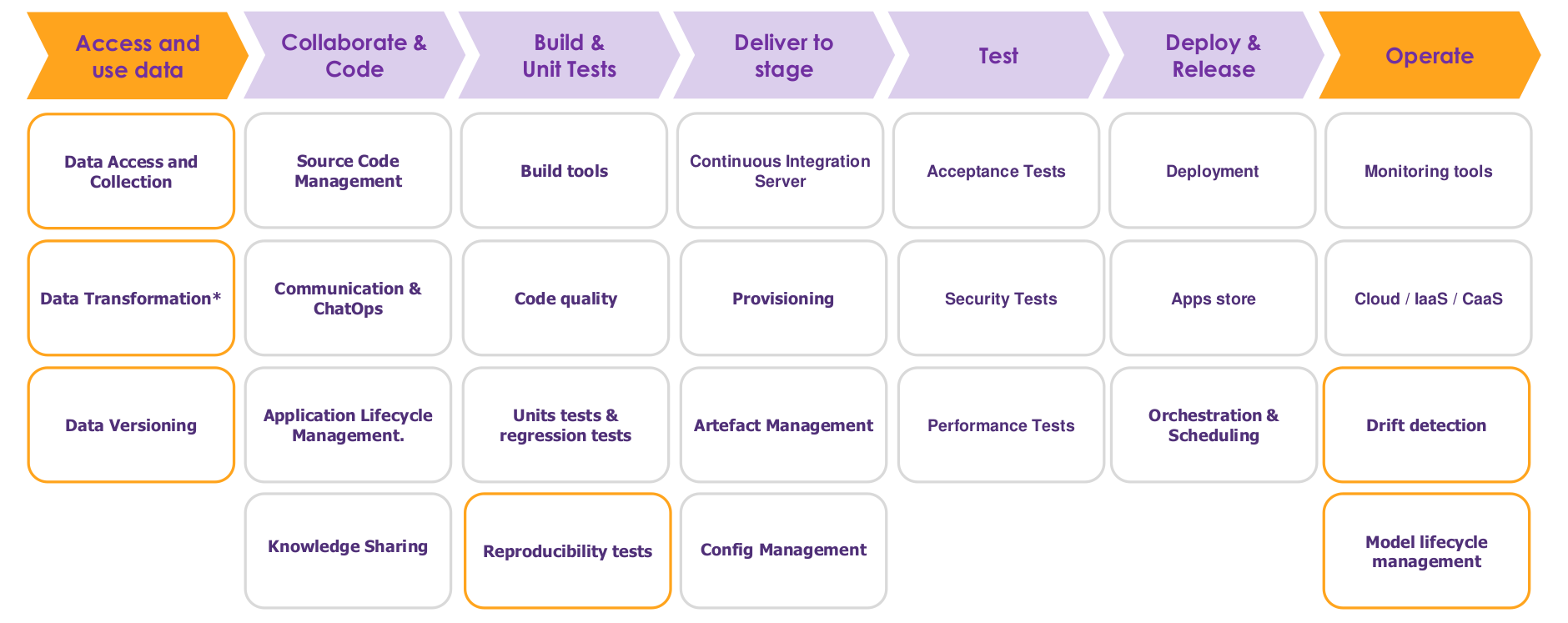
Retours d’expérience globaux à l’industrialisation des projets
Pour savoir en amont s’il est souhaitable d’industrialiser un POC de data science il est indispensable de se poser les questions suivantes :
- Quelle est la valeur ajoutée « business » du projet, quantifiée par son ROI (Return on investment) ?
- Quelle métrique métier utiliser pour évaluer la performance industrielle du modèle ?
- Quelle est la complexité/le coût de la mise en production ?
- Peut-on avoir facilement accès à un sponsor chez le client, venant du métier et en position de responsabilité, pour conduire le changement et inciter les équipes à travailler ensemble sur le projet ?
Quand on industrialise un POC, on ne se contente pas de prendre le modèle le plus performant. On essaie plutôt d’avoir le meilleur compromis entre performance du modèle, complexité de déploiement et explicabilité du modèle. On regarde également le coût de la maintenance une fois le modèle déployé.
Très souvent, un modèle n’aura pas les mêmes performances dans un environnement de développement et de validation. Afin d’anticiper les performances d’un modèle en production, des stratégies existent, telles que :
- Shadow deployment : faire des prédictions sans les utiliser
- A|B testing : utiliser des prédictions pour une partie des données et comparer les performances du système en production avec et sans le modèle.
- Decision support : le modèle en production est utilisé pour assister le processus actuel manuel qui est conservé dans un premier temps
- Full replacement : le processus actuel est entièrement remplacé par le modèle en production
Pour évaluer les scénarios d’intégration, on regarde des éléments tels que l’évaluation du modèle, la plus-value apportée par le modèle, la facilité de déploiement, le risque lié à un raté du modèle ainsi que l’adaptabilité du système déployé en cas de changement d’infrastructures.
Une fois l’algorithme codé, le passage du notebook à la production se fait via :
- La mise au propre du code : le code d’analyse et d’apprentissage des données est traduit en un exécutable ou un package utilisable par une interface. Une attention toute particulière est portée à la qualité du code. Les consultants s’assurent également que le code répond aux besoins du métier.
- La gestion des données : un processus rigoureux de collecte, transformation et versionning des données est fait. On vérifie que le modèle ne dévie pas avec les nouvelles données utilisées après son entraînement. On vérifie la consistance des résultats en fonction du code et des données.
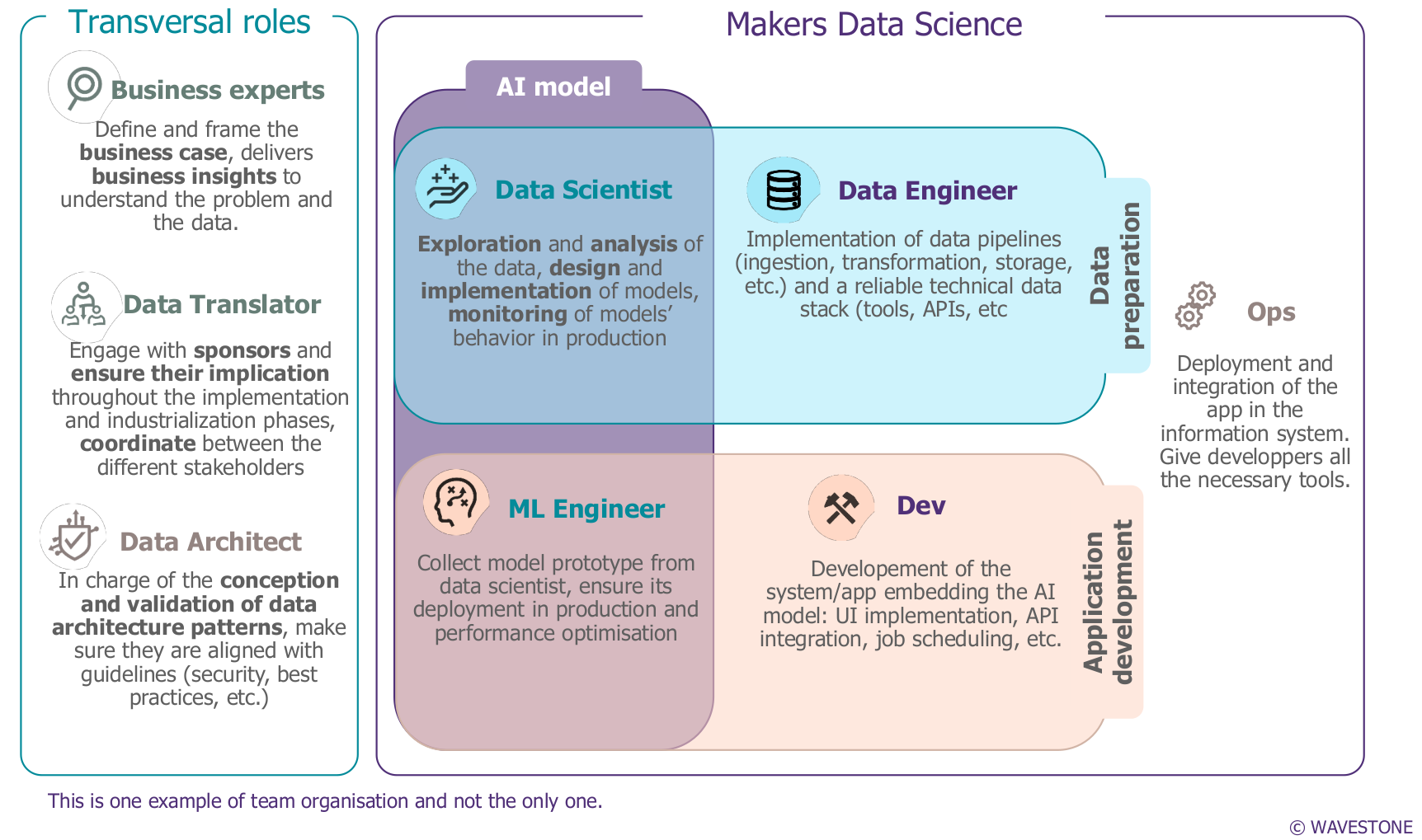
Exemple d’organisation d’équipe
Le Data Scientist va explorer et analyser les données. Il va également implémenter et monitorer les modèles d’apprentissage statistique.
Le Data Engineer va créer et suivre le cycle de vie de la donnée et s’assurer via des métriques que les sources sont fiables.
Le Machine Learning Engineer collecte les prototypes des modèles, assure leur déploiement en production et l’optimisation des performances.
Le Développeur (« Dev ») va coder un système ou une application, un « écrin » pour le modèle, sous la forme d’une interface, d’une API ou autre.
Compte-rendu rédigé par Bertrand Coureaud, Julien Maksoud et Adrien Senet, étudiants du Mastère Spécialisé Big Data promotion 2020-2021.
Illustration : photo de Freepik – Freepik.com