Natixis : la data science pour optimiser les activités back-office
lundi 24 juin 2019
Jeudi 4 avril 2019, nous avons eu l’honneur d’accueillir des représentants du pôle Data de la société Natixis. Mikaël Le Bars, data scientist (ancien du CES Data Scientist de Télécom Evolution), Florian Caringi, leader big data (ancien de Télécom Bretagne – IMT Atlantique) et Liosha Li, data analyste, sont venus nous présenter les différentes utilisations de la data science chez Natixis. Ces applications étant essentiellement des solutions innovantes au niveau de leur back office (logiciels internes) et au niveau de leurs infrastructures.
Natixis est une entreprise du groupe BPCE regroupant la Caisse d’Épargne et la Banque Populaire. Le groupe dégage environ 24 milliards de revenus nets par an et a aujourd’hui plus de 31 millions de clients. Quant à Natixis, l’entreprise reste très solide avec un revenu net de 10 milliards en 2017 et une croissance forte de 10%. Elle se place aujourd’hui comme étant un assureur de premier plan en France avec plus 21 000 employées et une présence dans 38 pays.
Les principales expertises du groupe Natixis portent sur : la gestion d’actifs et de fortune, l’assurance, la banque de grande clientèle et les services financiers spécialisés. Natixis cherche à amener des solutions sûres, innovantes et ingénieuses sur ces domaines grâce à la data science.
L’introduction du big data à Natixis a commencé en 2014 à travers un plan de digitalisation de la société et le choix de Hortonworks comme distribution de Hadoop et qui s’est fortement poursuivi jusqu’en 2018 comme le montre la figure ci-dessous :
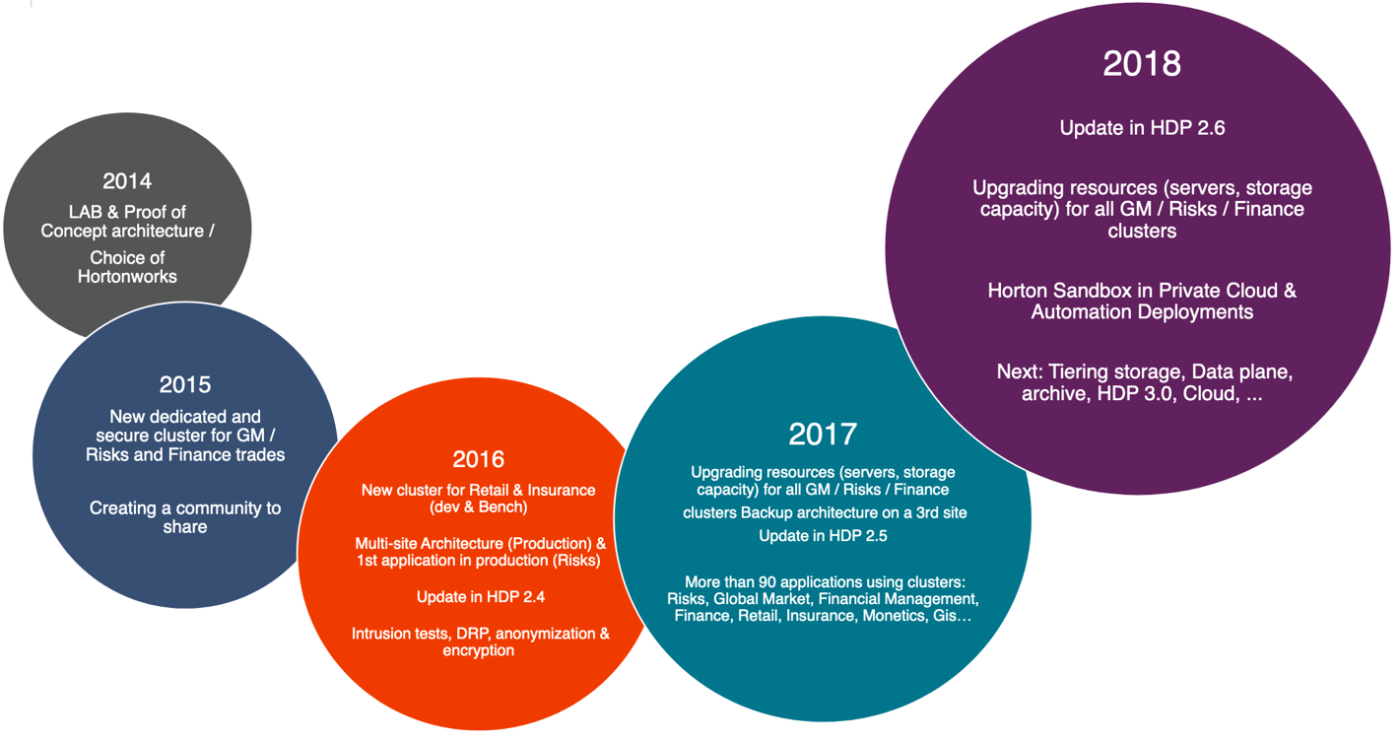
Natixis a mis en place deux plateformes Hadoop : une plateforme BGC (banque de grande clientèle) & DFO (direction fonctionnelle et risque) destinée aux clients et une autre destinée au Retail.
La plateforme BGC est utilisé pour des tâches de banque d’investissement, financements structurés, marchés de capitaux et de solutions de commerce et de trésorerie pour de grands clients. Avec la BCG, Natixis apporte son expertise dans quatre secteurs stratégiques : l’énergie et ressources naturelles, l’infrastructures, aviation et l’immobilier.
La plateforme Retail axe son activité principalement les fonctions supports et porte sur les activités de :
- l’assurance (assurances de personnes et assurances non vie),
- des services financiers spécialisés (solutions de paiement, cautions et garanties, crédit, bail …)
- la gestions d’actifs (assurance vie, actions, immobilier et capital investissement), de gestions de fortunes (gestion financière, ingénierie patrimoniale, crédit) et de l’épargne.
Les conférenciers ont abordé ensuite un cas d’usage de la science de données. Il s’agit d’implémenter un modèle de machine learning permettant de prédire les retards sur des deals. La figure ci-dessous illustre les étapes du déploiement d’un algorithme de machine learning et le flux de données nécessaire à sa mise en production :
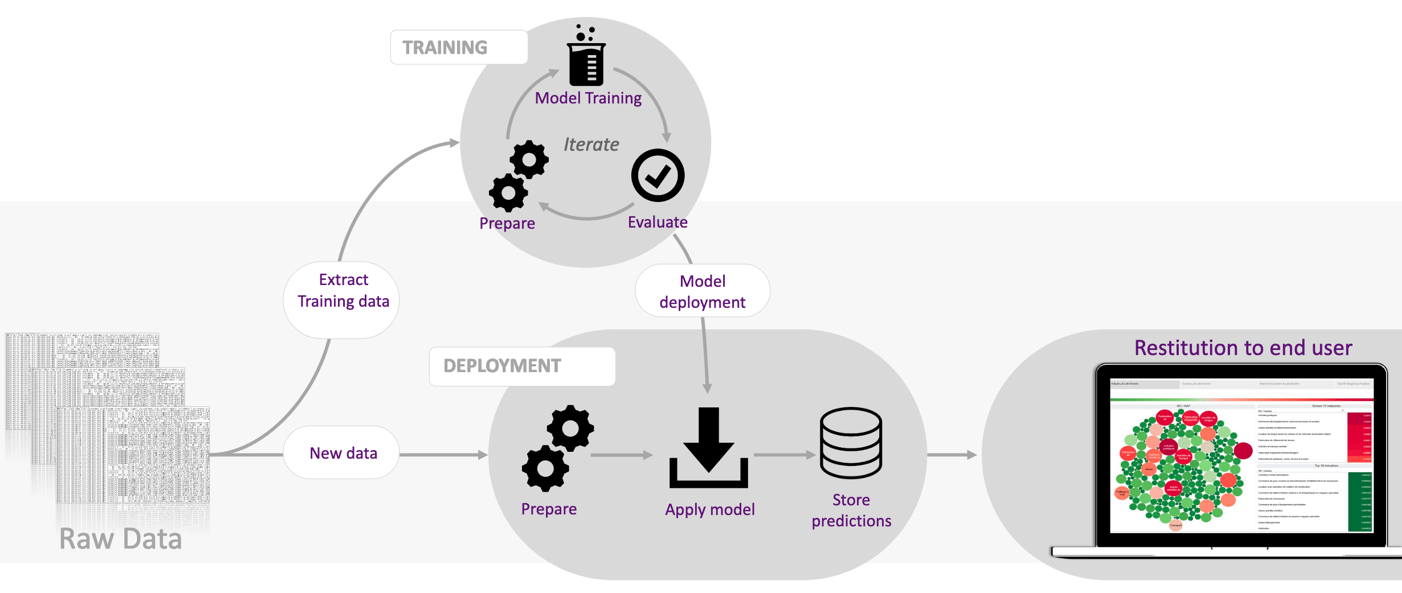
Comme on peut le voir dans la figure ci-dessus, le but de l’équipe est d’aider les métiers à mieux comprendre les éléments de complexités des deals en les modélisant afin de les aider dans leur quotidien. Pour cela l’équipe Big Data va permettre l’exploration de centaines de tables, l’extraction de manière itérative de celle-ci et la transformation de la données extraites (cleaning, binarisation, regroupements). De plus, les différents traitements sont packagés en librairies Python afin de faciliter leurs exportations et leurs utilisations.
Ensuite, dans la partie de training, des modèles sont préparés sur les données traitées, entraînés et évalués afin d’être facilement mis à disposition. Les modèles sont ensuite appliqués dans une partie de déploiement sur de nouvelles données pour faire des analyses et des prédictions de manière régulière.
Enfin les résultats sont restitués aux utilisateurs finaux grâce à de la data visualisation.
L’une des grandes forces de l’infrastructure de Natixis décrite ci-dessus est l’incorporation de l’outil Indexima dans le stockage des différents modèles et de leurs résultats. Indexima est un accélérateur business intelligence (BI) performant qui relie les sources de données aux supports de visualisation.
Les modèles sont ainsi facilement accessibles comme des requêtes SQL par exemple ci-dessous la création d’un modèle de random forest sur les retards de deals :

Ce système présente de grands avantages :
- L’utilisation d’un langage unique SQL,
- Aucun mouvement de données,
- Un seul environnement de travail,
- Aucun packaging,
- Des itérations rapides,
- Les étapes de transformations de data sont en partie automatisées.
Rappelons que lors de cette présentation, les conférenciers ont insisté sur le besoin de data ingénieurs sur le marché. Ceux-ci leur apparaissent essentiels dans l’établissement d’un projet big data, ils participent à la construction et au maintien de l’infrastructure data et apportent aussi une expertise sur l’analyse de données et l’établissement des algorithmes de machine learning. Ainsi si vous êtes à la recherche d’opportunités en tant que data ingénieur dans le secteur de la banque n’hésitez pas à les contacter !
Compte-rendu rédigé par Mohamed Dhaoui et Stéphane Peillet, étudiants du Mastère Spécialisé Big Data de Télécom Paris, promotion 2018-2019.