Les plateformes data science d’application de BearingPoint
lundi 20 juillet 2020
L’activité data de BearingPoint prend son essor en 2012 avec l’achat d’Hypercube, un algorithme de machine learning qui est embarqué aujourd’hui sur la plateforme data éponyme dans le « cloud » et qui constitue la base de ses solutions clients. L’équipe d’Advanced Analytics s’appuie sur la pluridisciplinarité pour bâtir son équipe de Data Science : statisticiens, data scientists, mais aussi data analysts, data engineers, data architects et développeurs. Cette pluridisciplinarité permet de créer une synergie au sein de l’équipe pour fournir l’essentiel des compétences qui sont nécessaires à la réalisation d’un projet data.
L’offre de l’équipe Advanced Analytics de BearingPoint s’articule en 3 points indépendants mais complémentaires : l’offre « Data Lake as a service », l’offre « Data Science as a Service » et l’offre autour de développement de solution dite « AI-driven Solution ».
- Datalake as a Service : cette offre propose de fournir une solution clef en main de Data Lake dans le cloud facilitant l’accès à la donnée en cassant les silos de données métiers, permettant ainsi une utilisation de la donnée simplifiée ainsi qu’une valorisation de la donnée accélérée.
- Data science as a Service : cette offre propose de réaliser des cas d’usage métiers orientés data.
- AI-driven Solution : cette offre inclut la mise en production des modèles et solutions de machine learning et le développement de web applications.
Un outil commun pour toutes les solutions applicatives
Hypercube représente la base commune des solutions verticalisées qui sont développées pour un secteur ou une industrie particulière. Nous verrons plus loin quelques exemples de ces verticaux.
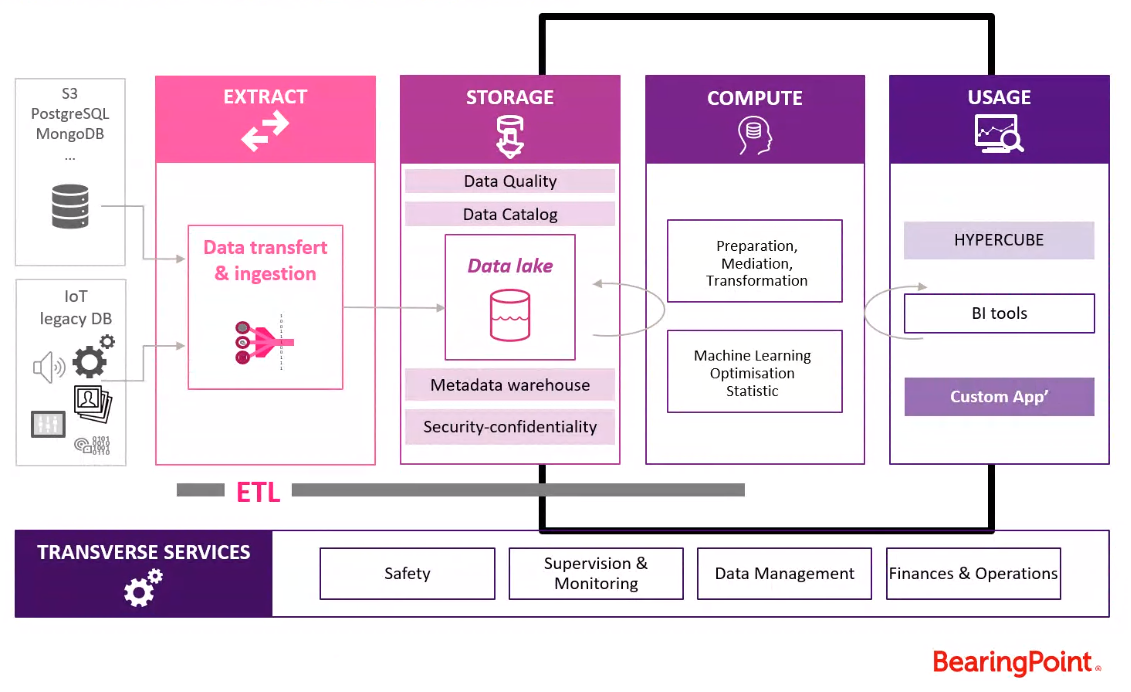
La plateforme repose sur 4 briques fonctionnelles qui restituent la chaine de traitement de valeur de la donnée.
- Extraction : saisir la data à sa source (IoT, bases de données comme MongoDb), puis nettoyer la donnée brute au moyen de codes d’ingestion.
- Stockage : s’articule sur la notion primordiale de datalake ou data warehouse. Le stockage s’accompagne d’un système de mise en qualité de la donnée, de processus de catalogues pour le référencement. L’idée est celle de « data gouvernance », c’est-à-dire produire un accès facile, rapide, sécurisé et exhaustif (incluant notamment les métadata) de la donnée.
- Calcul : rassemble les algorithmes de machine learning et de recherche opérationnelle. L’idée est de parvenir à la fois à stocker la donnée de façon intelligente tout en extrayant les infos utiles pour l’utilisateur.
- Usage : les interfaces utilisateurs qui sont directement connectées à la brique de stockage afin d’utiliser la donnée (visualisation, tableau de bord, modèles prédictifs …)
Une ultime couche se superpose à ces quatre composantes : les services transverses, pour maintenir et garantir l’intégrité du stockage et du traitement cloud.

La solution HyperCube est la plateforme de data science développée par l’équipe d’Advanced Analytics qui permet aux utilisateurs d’extraire de la valeur de leurs données en utilisant intuitivement et simplement des outils de data science. La plateforme HyperCube est utilisée pour un large éventail de business case comme l’analyse de fraude ou bien l’optimisation des ressources, l’identification de leviers d’optimisation de rendement, ou de satisfaction client. HyperCube est le socle technique sur lequel sont construits les applications verticalisées dont voici deux exemples.
Nitro, un outil de prédiction des stocks pour les points de vente pour la presse
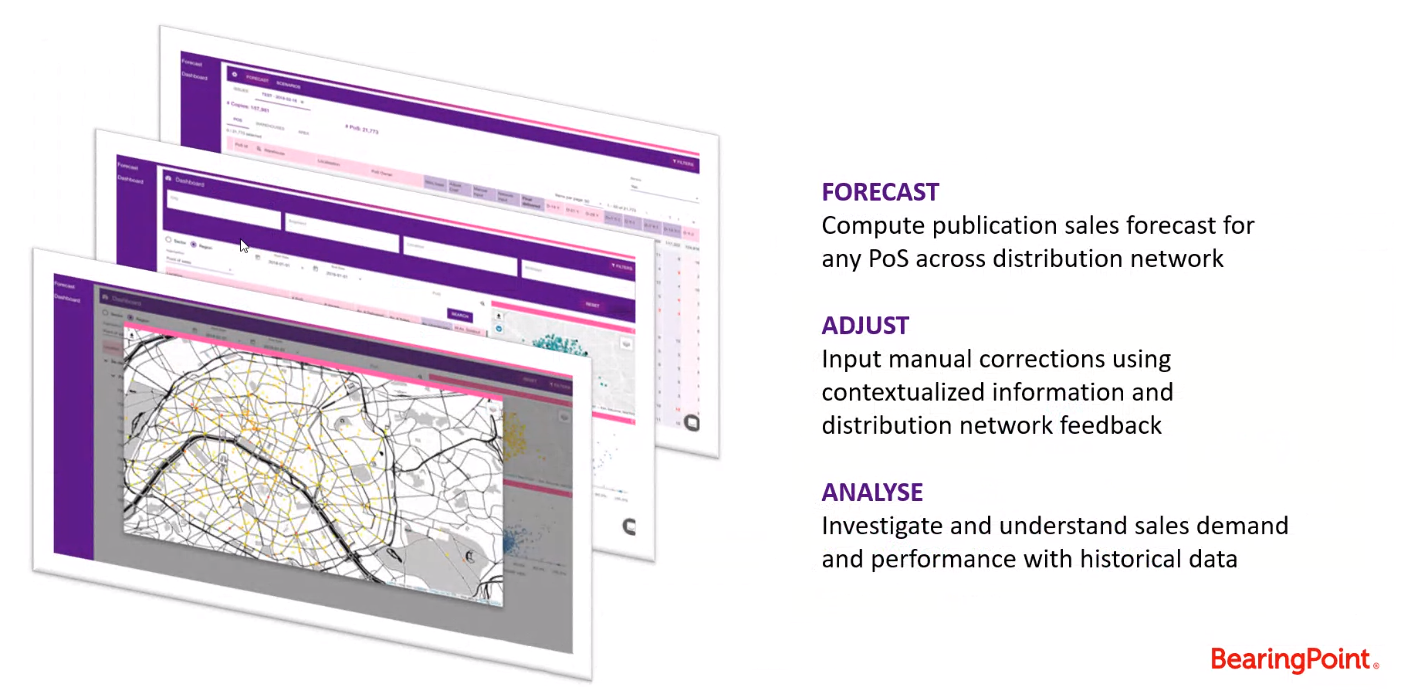
Nitro est le vertical d’HyperCube dédié à la prédiction des stocks pour l’industrie de la presse papier. C’est une plateforme rassemblant un ensemble d’algorithmes créés et mis au point spécifiquement pour prédire quotidiennement la quantité de journaux à expédier pour chaque référence et chaque point de vente du réseau.

Le système est basé sur l’analyse des séries temporelles, ce qui implique tout un processus de collecte, création et nettoyage de la donnée en amont qui est automatisé et appliqué « à la volée » tous les matins lors de la mise à jour des données grâce à un système d’ETL automatique et développé sur mesure.
Nitro est aujourd’hui utilisé quotidiennement par les équipes des acteurs de la presse Française pour générer les prédictions des stocks et également pour analyser l’historique de la vie du réseau.
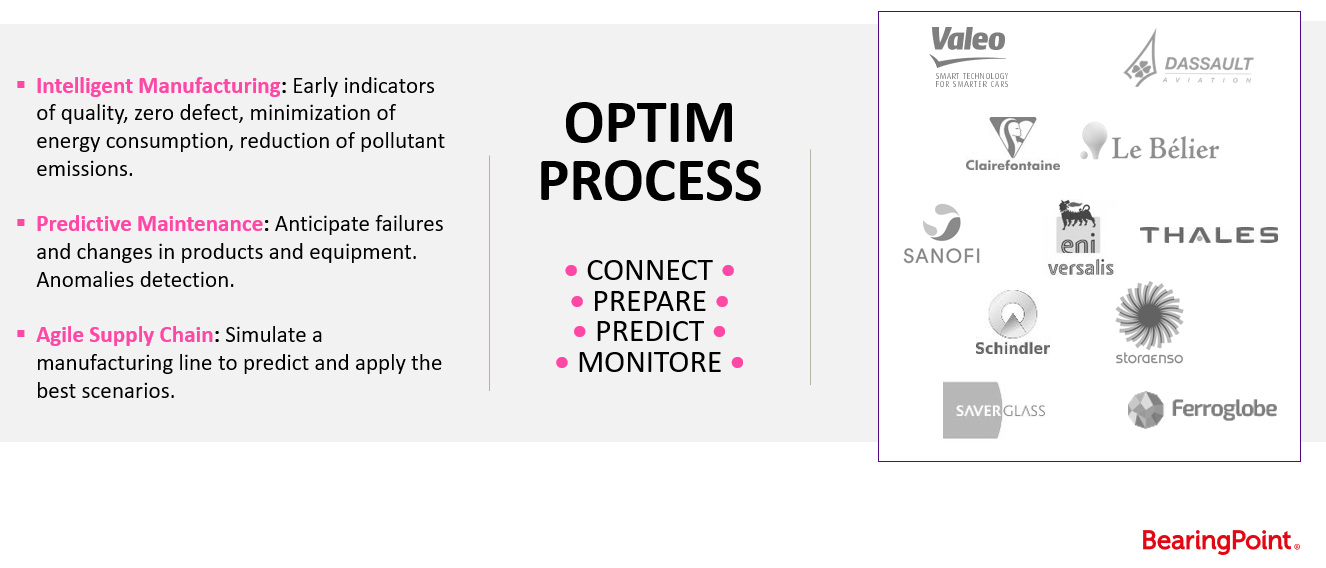
OptimProcess : La solution d’optimisation des processus de production
OptimProcess est le vertical d’HyperCube dédié à l’Industrie 4.0. OptimProcess a été conçu spécifiquement pour les industries de fabrication et de processus.
Il permet l’analyse des causes racines de processus ainsi que leur optimisation, mais également d’adresser des problématiques de maintenance préventive. L’aspect capital de l’application est la connexion à la donnée. La plateforme doit être capable de cartographier l’ensemble des processus afin de mettre en place la traçabilité de la donnée d’usine. La plateforme dispose également de connecteurs IoT permettant ainsi un suivi en temps réel de données provenant par exemple de capteurs. Le cœur de la solution intègre un large éventail d’algorithmes dédiés à l’analyse et au traitement des séries temporelles.
Compte-rendu rédigé par Romain Legrand, étudiant de la promotion 2019-2020 du Mastère Spécialisé Big Data de Télécom Paris.